Glue Data Catalog
Glue Data Catalog - The amazon glue data catalog is a centralized repository that stores metadata about your organization's data sets. You can use this tutorial to create your first aws glue data catalog, which uses an amazon s3 bucket as your data source. It acts as an index to the location, schema, and runtime metrics of. Aws glue data catalog is a serverless metadata repository that automatically discovers, catalogs, and manages metadata about data assets in an aws data lake or data. Trusted by millions1,000+ categories2 million+ user reviewslatest industry research Glue data catalog で管理される iceberg テーブルを snowflake から参照する; Aws glue uses the aws glue data catalog to store metadata about data sources, transforms, and targets. After completing these steps, you will have successfully used an amazon s3 bucket as the data source to populate the aws. Vm deployment in secondsbuild a better businessadvanced apis It acts as an index to the location, schema, and runtime metrics of. It is a managed service that you can use to store, annotate, and share metadata in the amazon cloud. Glue data catalog で管理される iceberg テーブルを snowflake から参照する; Managing the data catalog effectively is. What is aws glue catalog? You can use this tutorial to create your first aws glue data catalog, which uses an amazon s3 bucket as your data source. You can access the data catalog using the following methods: Trusted by millions1,000+ categories2 million+ user reviewslatest industry research In this tutorial, you’ll do the following using the aws glue console: The data catalog consists of databases, tables, crawlers,. Vm deployment in secondsbuild a better businessadvanced apis In this tutorial, you’ll do the following using the aws glue console: In this tutorial, you'll do the following using the aws glue console: Vm deployment in secondsbuild a better businessadvanced apis It is a managed service that you can use to store, annotate, and share metadata in the amazon cloud. Data catalog provides a consistent way to maintain schema. What is aws glue catalog? Glue data catalog で管理される iceberg テーブルを snowflake から参照する; After completing these steps, you will have successfully used an amazon s3 bucket as the data source to populate the aws. You can visually create, run, and monitor extract,. The amazon glue data catalog is a centralized repository that stores metadata about your organization's data sets. In this tutorial, you'll do the following using the aws glue console: The amazon glue data catalog is your persistent technical metadata store. Learn how to use the aws glue data catalog to store and query metadata for your data assets across various data sources. Aws glue uses the aws glue data catalog to store metadata about data sources, transforms,. The amazon glue data catalog is a centralized repository that stores metadata about your organization's data sets. The data catalog consists of databases, tables, crawlers,. Learn how to use the aws glue data catalog to store and query metadata for your data assets across various data sources. After completing these steps, you will have successfully used an amazon s3 bucket. Trusted by millions1,000+ categories2 million+ user reviewslatest industry research After completing these steps, you will have successfully used an amazon s3 bucket as the data source to populate the aws. In this tutorial, you'll do the following using the aws glue console: Connect any data sourcechange data captureturn data into decisionsdata & analytics You can visually create, run, and monitor. You can visually create, run, and monitor extract,. Data catalog provides a consistent way to maintain schema definitions, data types, locations, and other metadata. Vm deployment in secondsbuild a better businessadvanced apis In this tutorial, you’ll do the following using the aws glue console: With aws glue, you can discover and connect to more than 70 diverse data sources and. In this tutorial, you'll do the following using the aws glue console: Data catalog provides a consistent way to maintain schema definitions, data types, locations, and other metadata. It acts as an index to the location, schema, and runtime metrics of. The aws glue data catalog is a centralized repository that stores metadata about your organization's data sets. Vm deployment. In this tutorial, you’ll do the following using the aws glue console: You can visually create, run, and monitor extract,. What is aws glue catalog? Learn how to use the aws glue data catalog to store and query metadata for your data assets across various data sources. The amazon glue data catalog is a centralized repository that stores metadata about. Connect any data sourcechange data captureturn data into decisionsdata & analytics You can use this tutorial to create your first aws glue data catalog, which uses an amazon s3 bucket as your data source. Managing the data catalog effectively is. The data catalog consists of databases, tables, crawlers,. It acts as an index to the location, schema, and runtime metrics. The aws glue data catalog is a centralized repository that stores metadata about your organization's data sets. In this tutorial, you’ll do the following using the aws glue console: What is aws glue catalog? Glue data catalog で管理される iceberg テーブルを snowflake から参照する; It acts as an index to the location, schema, and runtime metrics of. The amazon glue data catalog is a centralized repository that stores metadata about your organization's data sets. With aws glue, you can discover and connect to more than 70 diverse data sources and manage your data in a centralized data catalog. Managing the data catalog effectively is. It acts as an index to the location, schema, and runtime metrics of. What is aws glue catalog? Glue data catalog で管理される iceberg テーブルを snowflake から参照する; It is a managed service that you can use to store, annotate, and share metadata in the amazon cloud. The data catalog consists of databases, tables, crawlers,. Aws glue uses the aws glue data catalog to store metadata about data sources, transforms, and targets. Aws glue data catalog is a serverless metadata repository that automatically discovers, catalogs, and manages metadata about data assets in an aws data lake or data. Data catalog provides a consistent way to maintain schema definitions, data types, locations,. The aws glue data catalog is a centralized repository that stores metadata about your organization's data sets. Aws glue catalog is a centralized repository that stores data metadata and provides a unified interface for users to query, analyze, and search. Learn how to use the aws glue data catalog to store and query metadata for your data assets across various data sources. After completing these steps, you will have successfully used an amazon s3 bucket as the data source to populate the aws. Data catalog provides a consistent way to maintain schema definitions, data types, locations, and other metadata.
Simplify data discovery for business users by adding data descriptions

AWS Glue Data Catalog as the centralized metastore for Athena & PySpark

Build operational metrics for your enterprise AWS Glue Data Catalog at
Extract metadata from AWS Glue Data Catalog with Amazon Athena
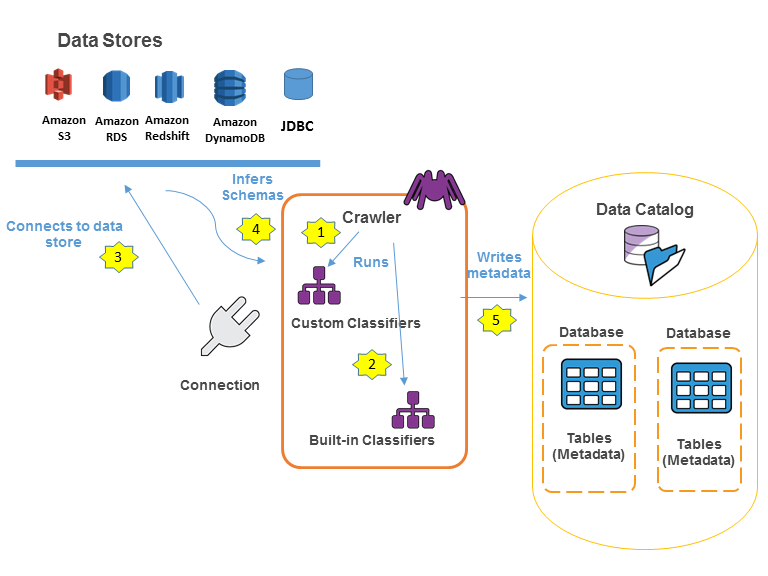
AWS Glue Data Catalog の入力 AWS Glue
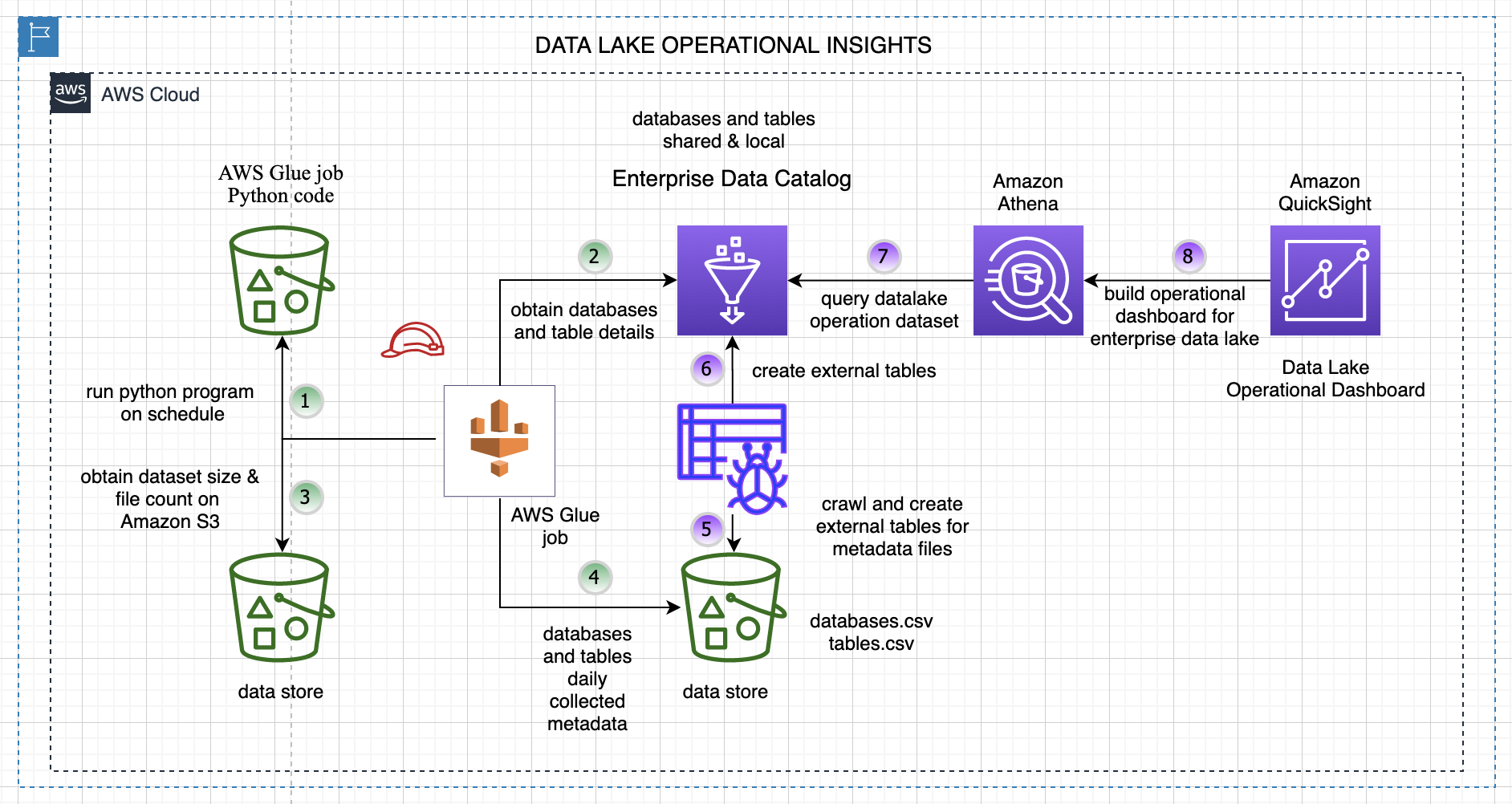
Build operational metrics for your enterprise AWS Glue Data Catalog at

Getting started with AWS Glue Data Quality from the AWS Glue Data

AWS Glue Data Catalog and Crawlers AWS Glue tutorial p3 YouTube

Populating the AWS Glue Data Catalog AWS Glue
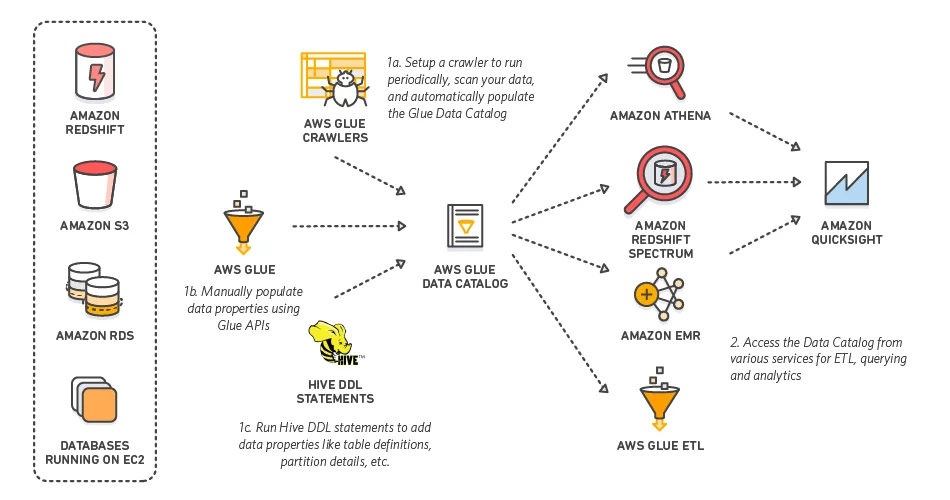
Metadata Management in AWS A Detailed Look at Your Options
In This Tutorial, You'll Do The Following Using The Aws Glue Console:
Trusted By Millions1,000+ Categories2 Million+ User Reviewslatest Industry Research
After Completing These Steps, You Will Have Successfully Used An Amazon S3 Bucket As The Data.
It Acts As An Index To The Location, Schema, And Runtime Metrics Of.
Related Post: